在网站跳出率的公式中,(1)和(2)分别是?()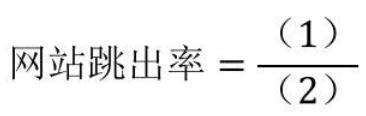
A、网站跳出的人数、总访问人数
B、仅浏览了一个页面的人数、总访问数
C、进访问两个页面的人数、总访问量
D、网站跳出的人数、总访问量
竞价排名相比搜索引擎收费登录,其不同之处在于
A.按照排名的时间长短收费
B.按照客户网站带来的实际访问量收费
C.借助搜索引擎这个平台来进行推广
D.不是按照客户网站带来的实际访问量收费
GoogleAnalytics(转化分析)通关()、()、视频播放次数等有价值的操作指标,了解访问者购买产品的意愿,进而调整网站和营销计划以实现企业的业务目标。
A、衡量销售量、下载次数
B、衡量访问量、访问次数
C、衡量销售量、访问次数
D、衡量访问量、下载次数
Alexa排名是指网站访问量的世界排名,其在网络营销中的主要作用包括()
A、了解同类网站访问量的相对高低
B、分析自己运营网站排名的变化情况
C、分析判断网站运营中可能存在的问题
D、了解竞争者网站的基本情况
一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜素结果中比较靠前的地方。这个方案很容易想到,但是解决的方法却没有想象的那么简单。在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的“重要程度”——可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门“刷访问量”的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢?就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫PageRank的算法,这种算法的主要思想是:越“重要”的网页,页面上的链接质量也越高,同时越容易被其它“重要”的网页链接,于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。不过要强调的是,虽然PageRank是谷歌搜索结果排序的重要依据,谷歌也以此发家,但是它并不是全部依据——实际上,谷歌发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。关于PageRank算法,下列说法错误的是( ) A.PageRank算法提出了一种新的数学统计方法B.PageRank算法使谷歌在搜索引擎的竞争中脱颖而出C.PageRank算法改变了以网页访问量作为排序依据的传统想法D.PageRank算法能够更准确、更省力地统计出网页的访问量
一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜索结果中比较靠前的地方。这个问题看起来很容易,但是解决的方法却没有想象的那么简单。
在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是因为只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的“重要程度”--可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门“刷访问量”的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢?
就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫做PageRank的算法,这种算法的主要思想是:越“重要”的网页,页面上的链接质量也越高,同时越容易被其他“重要”的网页链接。于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。
不过要强调的是,虽然PageRank是Google搜索结果排序的重要依据并以此发家,不过它并不是全部依据--实际上,Google发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。
关于PageRank算法,下列说法错误的是:
A.PageRank算法提出了一种新的数学统计方法
B.PageRank算法使谷歌在搜索引擎的竞争中脱颖而出
C.PageRank算法改变了以网页访问量作为排序依据的传统算法
D.PageRank算法能够更准确、更省力地统计出网页的访问量
[单选]关于PageRank算法,下列说法错误的是()一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜素结果中比较靠前的地方。这个方案很容易想到,但是解决的方法却没有想象的那么简单。 在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的“重要程度”——可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门“刷访问量”的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢? 就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫PageRank的算法,这种算法的主要思想是:越“重要”的网页,页面上的链接质量也越高,同时越容易被其它“重要”的网页链接,于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。 不过要强调的是,虽然PageRank是谷歌搜索结果排序的重要依据,谷歌也以此发家,但是它并不是全部依据——实际上,谷歌发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。
A.PageRank算法提出了一种新的数学统计方法
B.PageRank算法使谷歌在搜索引擎的竞争中脱颖而出
C.PageRank算法改变了以网页访问量作为排序依据的传统想法
D.PageRank算法能够更准确、更省力地统计出网页的访问量
一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜索结果中比较靠前的地方。这个问题看起来很容易,但是解决的方法却没有想象的那么简单。
在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是因为只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的“重要程度”--可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门“刷访问量”的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢?
就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫做PageRank的算法,这种算法的主要思想是:越“重要”的网页,页面上的链接质量也越高,同时越容易被其他“重要”的网页链接。于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。
不过要强调的是,虽然PageRank是Google搜索结果排序的重要依据并以此发家,不过它并不是全部依据--实际上,Google发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。
根据文意,“刷访问量”会导致:
A.增加统计时间
B.影响统计精度
C.相应网站崩溃
D.网页错误评价
[单选]根据文意,“刷访问量”会导致()一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜素结果中比较靠前的地方。这个方案很容易想到,但是解决的方法却没有想象的那么简单。 在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的“重要程度”——可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门“刷访问量”的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢? 就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫PageRank的算法,这种算法的主要思想是:越“重要”的网页,页面上的链接质量也越高,同时越容易被其它“重要”的网页链接,于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。 不过要强调的是,虽然PageRank是谷歌搜索结果排序的重要依据,谷歌也以此发家,但是它并不是全部依据——实际上,谷歌发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。
A.增加统计时间
B.影响统计精度
C.相应网站崩溃
D.网页错误评价
一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜素结果中比较靠前的地方。这个方案很容易想到,但是解决的方法却没有想象的那么简单。在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的“重要程度”——可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门“刷访问量”的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢?就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫PageRank的算法,这种算法的主要思想是:越“重要”的网页,页面上的链接质量也越高,同时越容易被其它“重要”的网页链接,于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。不过要强调的是,虽然PageRank是谷歌搜索结果排序的重要依据,谷歌也以此发家,但是它并不是全部依据——实际上,谷歌发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。搜索引擎对网页排序的最基本思想是指() A.访问量越大排在越前面B.链接质量越高排在越前面C.和其他网页关系越密切排在越前面D.越重要排在越前面
[单选]搜索引擎对网页排序的最基本思想是指()一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜素结果中比较靠前的地方。这个方案很容易想到,但是解决的方法却没有想象的那么简单。 在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的“重要程度”——可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门“刷访问量”的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢? 就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫PageRank的算法,这种算法的主要思想是:越“重要”的网页,页面上的链接质量也越高,同时越容易被其它“重要”的网页链接,于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。 不过要强调的是,虽然PageRank是谷歌搜索结果排序的重要依据,谷歌也以此发家,但是它并不是全部依据——实际上,谷歌发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。
A.访问量越大排在越前面
B.链接质量越高排在越前面
C.和其他网页关系越密切排在越前面
D.越重要排在越前面
当网站拥有一定的访问量后,网络营销的目标将注重用户资源的价值化,而不仅仅是访问量的提升,取决于企业的经营策略和盈利模式,这是()。
A、网站稳定期推广的特点
B、网站增长期推广特点
C、网站发布初期推广的特点
D、网站策划与建设阶段网站的特点
关于PageRank算法,下列说法错误的是( )。
A.PageRank算法提出了一种新的数学统计方法
B.PageRank算法使谷歌在搜索引擎的竞争中脱颖而出
C.PageRank算法改变了以网页访问量作为排序依据的传统想法
D.PageRank算法能够更准确、更省力地统计出网页的访问量
题目 关于PageRank算法,下列说法错误的是( )。
A:PageRank算法提出了一种新的数学统计方法
B:PageRank算法使谷歌在搜索引擎的竞争中脱颖而出
C:PageRank算法改变了以网页访问量作为排序依据的传统想法
D:PageRank算法能够更准确、更省力地统计出网页的访问量
试题四(共15分)
阅读以下说明,回答问题l至问题3,将解答填入答题纸的对应栏内。
【说明】
某公司使用ASP开发商务网站,该商务网站具有商品介绍、会员管理、在线支付、物流管理和访客计数器等功能,采用Sqlserver数据库,数据库名为business,其中访客计数器表存储今日访问量、昨日访问量和总访问量等字段,其名称为counter。
【问题1】(6分)
ASP访问数据库一般采用ADO技术,ADO对象主要包含Connection对象、Command对象、Parameter对象、Recordset对象、Field对象和Error对象等。请根据ADO对象之间的关系,在空(1)~(6)处填写正确的对象名。

[单选]阅读下面的文章,回答问题。一个正常的搜索引擎,其核心功能自然是网页搜索。那搜索结果应该怎样排序才最好呢?实际上,在谷歌主导互联网搜索之前,人们为此伤透脑筋。很显然,搜索引擎应该把重要的网页放到搜素结果中比较靠前的地方。这个方案很容易想到,但是解决的方法却没有想象的那么简单。在谷歌诞生之前那段时间,流行的网页排名算法都很类似,它们都使用了一个非常简单的思想:越是重要的网页,访问量就会越大。许多大公司就通过统计网页的访问量来进行网页排名。但是这种排名算法有两个很显著的问题:一是只能够抽样统计,所以统计数据不一定准确,而且访问量的波动会比较大,想要得到准确的统计需要大量的时间和人力,还只能维持很短的有效时间;二是访问量并不一定能体现网页的"重要程度"——可能一些比较早接触互联网的网民还记得,那时有很多人推出了专门"刷访问量"的服务。有没有更好的方法,不统计访问量就能够为网页的重要度排序呢?就是在这种情况下,1996年初,谷歌公司的创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。在1999年,一篇以佩奇为第一作者的论文发表了,论文中介绍了一种叫PageRank的算法,这种算法的主要思想是:越"重要"的网页,页面上的链接质量也越高,同时越容易被其它"重要"的网页链接,于是,算法完全利用网页之间互相链接的关系来计算网页的重要程度,将网页排序彻底变成一个数学问题,终于摆脱了访问量统计的框框。不过要强调的是,虽然PageRank是谷歌搜索结果排序的重要依据,谷歌也以此发家,但是它并不是全部依据——实际上,谷歌发展到现在,已同时用了数百种不同的算法来确定最终显示给用户的搜索结果顺序。
OLAP系统和OLTP系统的主要区别包括()
A
OLTP系统主要用于管理当前数据,而OLAP系统主要存放的是历史数据
B
在数据的存取上,OLTP系统比OLAP系统有着更多的写操作
C
对OLTP系统上的数据访问量往往比对OLAP系统的数据访问量要大得多
D
OLAP系统中往往存放的是汇总的数据,而OLTP系统中往往存放详细的数据
在网络宣传中,对于个人网站友情链接是一种比较好的方式,下列关于友情链接说法不正确的是()。
A、友情链接是相互的
B、与访问量大的、优秀的个人主页相互交换链接则能大大地提高主页的访问量
C、网站标志制作得是否漂亮不重要
D、在自己的首页或专门做“友情链接”的专页上放置对方的链接并进行推荐
搜索引擎营销的效果表现为网站访问量的增加而不是直接销售。()
根据文意,“刷访问量”会导致( )。
A.增加统计时间
B.影响统计精度
C.相应网站崩溃
D.网页错误评价

